Do Vision and Text Cues Exhibit Evidential Coupling?
UFO: A Benchmark for Compositional Multimodal Reasoning in Unified Models

Abstract
Unified Foundation Models (UFMs), which support interleaved multimodal generation and understanding, have been proposed as a promising paradigm for reasoning about dynamic world states, yet it remains unclear whether the visual content they generate functions as grounded evidence for subsequent reasoning or merely as auxiliary output. Existing benchmarks largely evaluate generation and understanding as separate capabilities and do not test their functional dependence during reasoning.
We introduce UFO, a benchmark designed to evaluate whether UFMs generate and use image and text cues as evidence for compositional multimodal reasoning. UFO spans three cue types — state determination, state reconstruction, and state augmentation — which correspond to progressively smaller transformations of the underlying world state. Our analysis reveals a significant modality gap: models often achieve high prediction accuracy even when the generated visual cues exert limited influence on their decisions, indicating weakened evidential coupling and a reliance on textual shortcuts rather than robust cross-modal grounding.

Case Studies
For each task, we compare the model's generated textual and visual cues against the ground truth, and trace how they drive the final answer. Slide through all 10 tasks.

Hybridisation · State Determination

Chemical · State Determination

Multi-table · State Determination

Multi-view · State Determination

Inpainting · State Reconstruction

Exo-to-Ego · State Reconstruction

Jigsaw · State Reconstruction
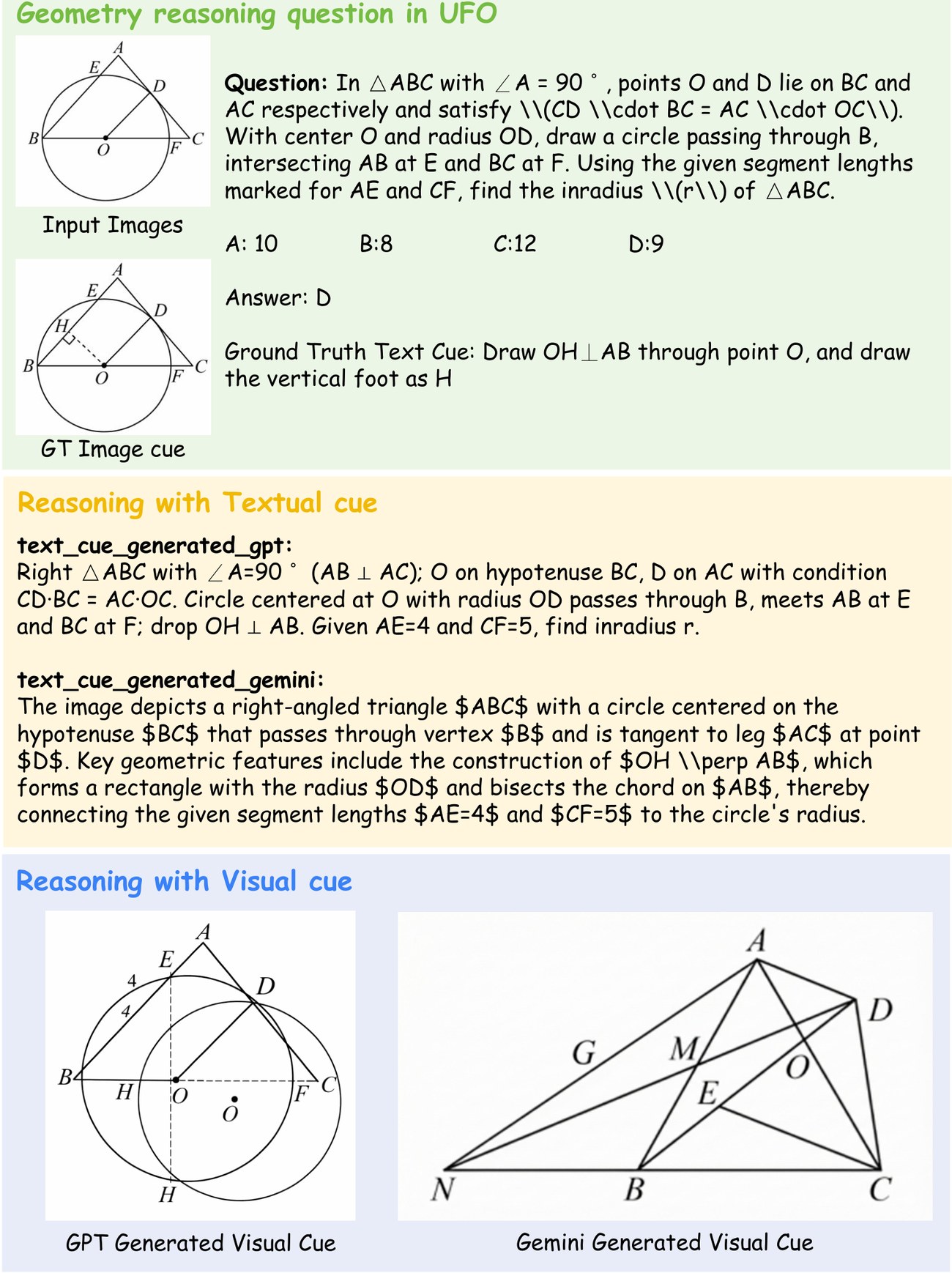
Geometric · State Augmentation
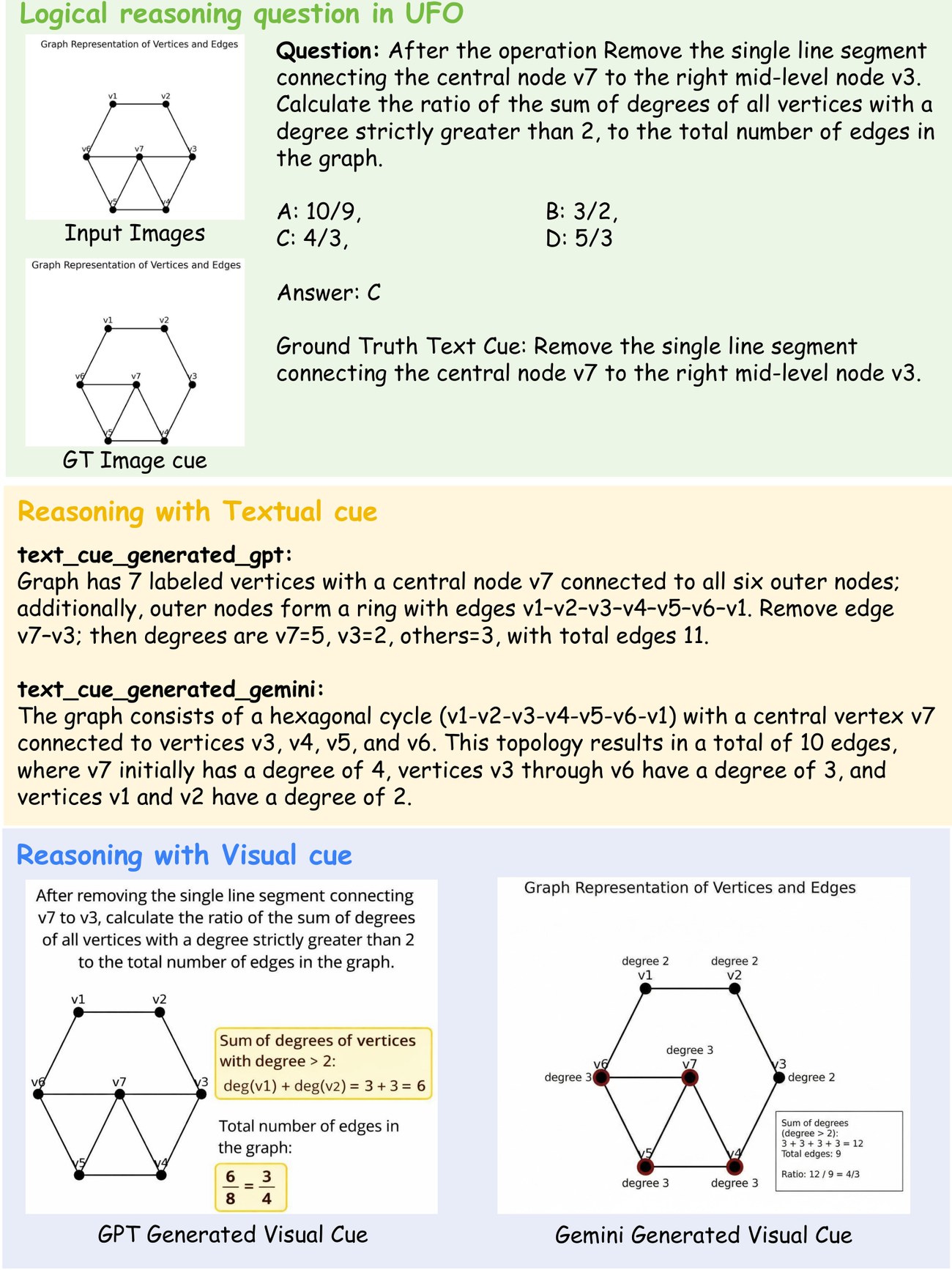
Logical · State Augmentation

Physics · State Augmentation
BibTeX
@inproceedings{ufo2026,
title = {Do Vision and Text Cues Exhibit Evidential Coupling?
UFO: A Benchmark for Compositional Multimodal Reasoning in Unified Models},
author = {Yang, Zhongyu and Xu, Dannong and Zhang, Yonghan and Chen, Kefan and
Wang, Xinyi and Xu, Yang and Pang, Wei and Yuan, Yingfang},
booktitle = {International Conference on Machine Learning (ICML)},
year = {2026}
}