
Zhongyu Yang
About Me
I am a Research Scientist at ModelBest, where I work on omni foundation models for video, audio, and language understanding. Previously, I was a research intern at Tencent Hunyuan (Qingyun Top Talent Program), where my research centered on omni-video understanding — jointly interpreting a video together with its accompanying audio and language (e.g., Script-a-Video, deep structured audio-visual captioning). I was also a remote research intern at Vision-CAIR, KAUST, advised by Mohamed Elhoseiny, and a research intern at SenseTime. I received my B.S. in Mathematics (minor in Management) from Lanzhou University.
My research seeks to advance multimodal models from surface-level recognition toward genuine understanding — reasoning about why events occur and what follows, with inferences grounded in evidence that is consistent across modalities and over time. My work spans four interconnected directions:
Research Interests
- Omni-Video Understanding: long-form, audio-visual, and tool-augmented video comprehension that integrates vision, audio, and language over time (SVAgentCVPR, ParaVTTech Report, Script‑a‑VideoTech Report)
- Compositional Multimodal Reasoning: evaluating and strengthening how models exploit cross-modal evidence when reasoning over evolving world states (UFOICML, InExAAAI, MERMAIDEMNLP, XRWWW)
- Generative Modeling as Evidence: leveraging generated images, sequences, and future states as intermediate evidence for understanding and prediction (WikiAutoGenICCV, ReCharSIGGRAPH Asia, Evolving Visual GenerationTech Report, CHATECCV)
- Efficient & Trustworthy Models: token compression and safety-oriented mechanisms that keep large multimodal and language models scalable and reliable (ScriptTMLR, SCOPEKDD)
In the long term, I aim to develop general-purpose multimodal systems that perceive, reason, and communicate across vision, audio, language, and action in dynamic, real-world environments.
I warmly welcome research collaborations and discussions on omni foundation models, multimodal reasoning, and audio-visual understanding — please feel free to reach out.
{kind=link}
News
- [2026.06] CHAT and MultiHaystack were accepted to ECCV 2026 🎉.
- [2026.05] SCOPE was accepted to KDD 2026 🎉.
- [2026.05] UFO was accepted to ICML 2026 🎉. The dataset and code are now open-sourced.
- [2026.02] EmoRes was accepted to ACL 2026 🎉.
- [2026.02] SVAgent and MeteoNet were accepted to CVPR 2026 🎉.
- [2026.01] XR was accepted to WWW 2026 🎉.
- [2025.11] InEx was accepted to AAAI 2026 🎉.
- [2025.10] Script was accepted to TMLR 2025 🎉.
- [2025.08] ReChar was accepted to SIGGRAPH Asia 2025 🎉.
- [2025.08] MERMAID was accepted to EMNLP 2025 (Main) 🎉.
- [2025.06] WikiAutoGen was accepted to ICCV 2025 🎉.
- [2025.03] We present WikiAutoGen for automated multimodal Wikipedia-style article generation. Featured in Hugging Face Daily Papers and reposted by AK.
- [2024.12] Started Remote Research Internship with Jun Chen and Mohamed Elhoseiny (KAUST), focusing on web-scale RAG systems for vision.
- [2024.11] Released ReChar: structure-preserving and user-aesthetic-enhanced character generation.
- [2024.05] Our paper Green Effect of Energy Transition Policy was accepted to Finance Research Letters (SSCI Q1 Top journal) 🎉.
- [2024.04] National Innovation Project funded: FPGA-Based AI Doctor, advised by Prof. Xinhua Wang.
- [2024.04] Joined CUHKSZ as Research Assistant with Ruimao Zhang, focusing on AI4Science and CV.
- [2024.03] Began Remote Research Internship with Yingfang Yuan at Heriot-Watt University on AIGC.
- [2024.01] Project UNet-Centric MambaMorph selected as Outstanding Undergraduate Project (TOP 0.1%) under Barley Plan, advised by Prof. Wenting Zhang.
- [2023.05] Paper Environmental Quality in OECD Countries was accepted to Renewable Energy (SCI Q1 Top journal) 🎉.
- [2023.03] As sophomore, led innovation project on Tropical Linear Representation of Chinese Monoids, advised by Prof. Wenting Zhang. [Tech Report] can be finding.
Experience
-
 Research Scientist, Omni Foundation Model, ModelBest (面壁智能)
Jul. 2026 – Present
Research Scientist, Omni Foundation Model, ModelBest (面壁智能)
Jul. 2026 – Present
-
 Research Intern, Tencent Qingyun Top Talent Program, Hunyuan, Tencent
Mar. 2026 – Jul. 2026
Research Intern, Tencent Qingyun Top Talent Program, Hunyuan, Tencent
Mar. 2026 – Jul. 2026
-
 Research Intern, General Perceptual Computing Group, SenseTime
Feb. 2025 – Feb. 2026
Research Intern, General Perceptual Computing Group, SenseTime
Feb. 2025 – Feb. 2026
-
 Remote Research Intern, BCML Lab, Heriot-Watt University
Mar. 2024 – Present
Remote Research Intern, BCML Lab, Heriot-Watt University
Mar. 2024 – Present
-
 Remote Research Intern at Vision-CAIR, KAUST
Dec. 2024 – Jan 2026
Remote Research Intern at Vision-CAIR, KAUST
Dec. 2024 – Jan 2026
-
 Research Assistant at LIAS Lab, CUHK (Shenzhen)
Apr. 2024 – Nov. 2024
Research Assistant at LIAS Lab, CUHK (Shenzhen)
Apr. 2024 – Nov. 2024
-
 Data Analysis Assistant, iFLYTEK
Jun. 2023 – Aug. 2023
Data Analysis Assistant, iFLYTEK
Jun. 2023 – Aug. 2023
Selected Publications [ Google Scholar]
† Equal contribution * Corresponding author
-
 ICML 2026
ICML 2026
-
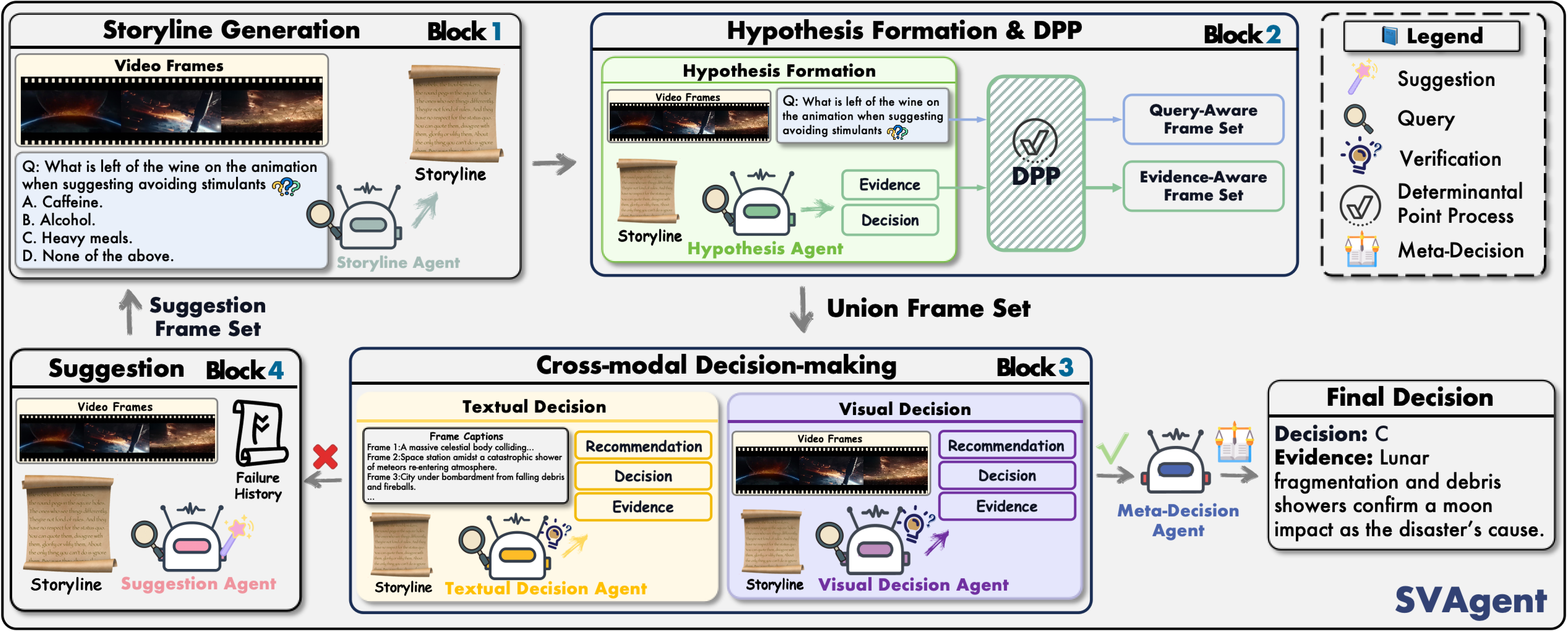 CVPR 2026
CVPR 2026
-
 ECCV 2026
ECCV 2026
-
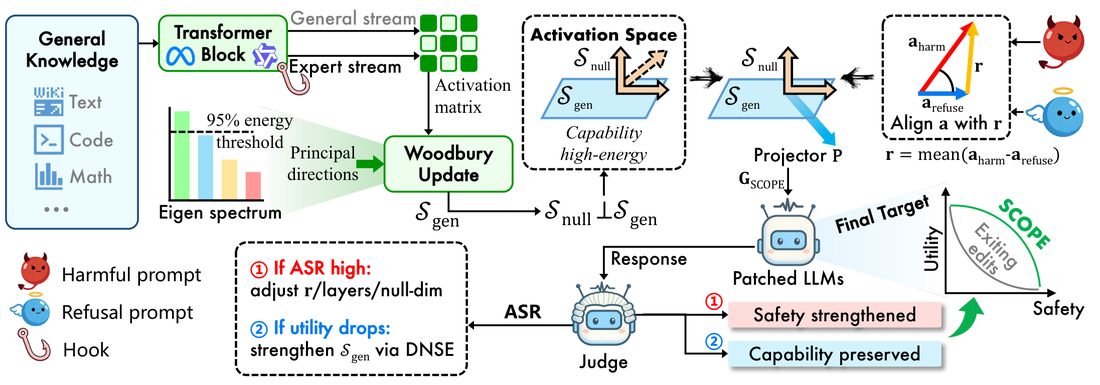 KDD 2026
KDD 2026
-
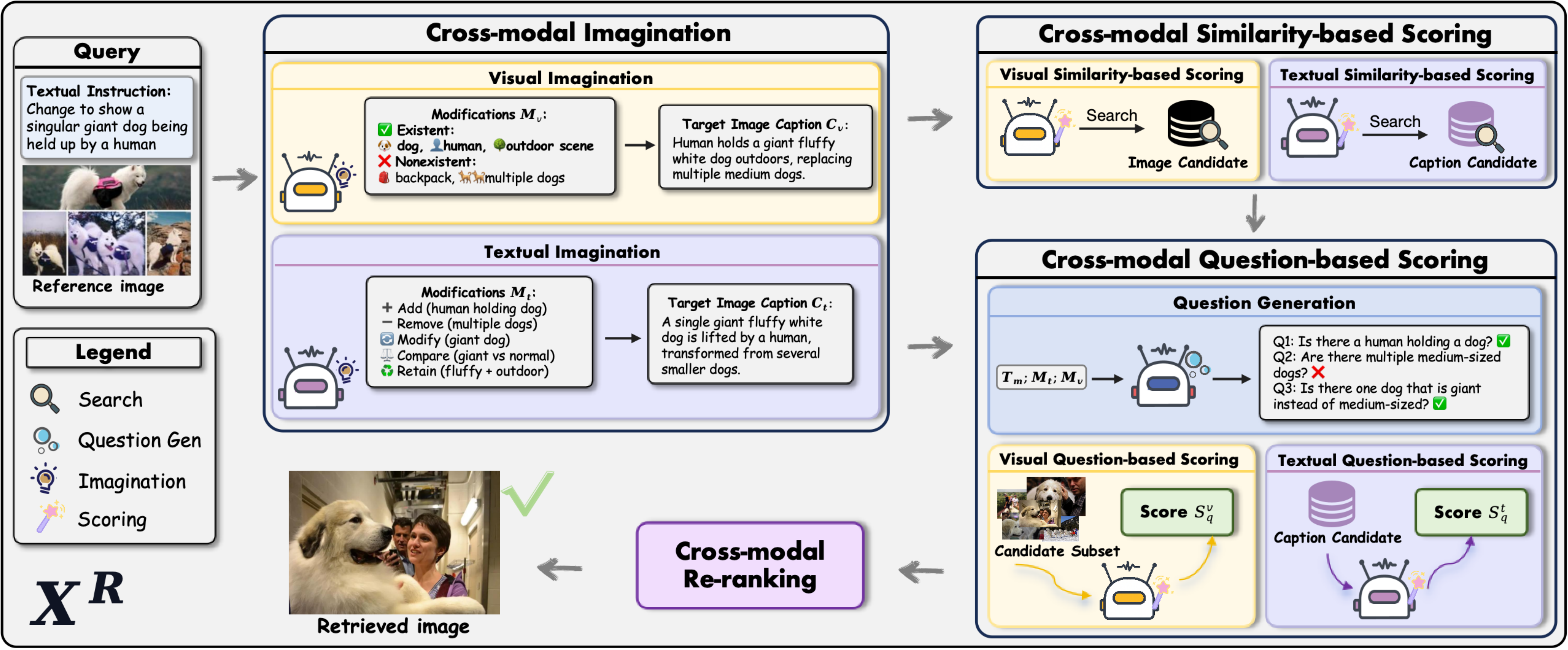 WWW 2026
WWW 2026
-
 ICCV 2025
ICCV 2025, Hugging Face Daily Papers
ICCV 2025
ICCV 2025, Hugging Face Daily Papers
-
 AAAI 2026
AAAI 2026
-
 TMLR 2025
TMLR 2025
-
 EMNLP 2025
EMNLP 2025
-
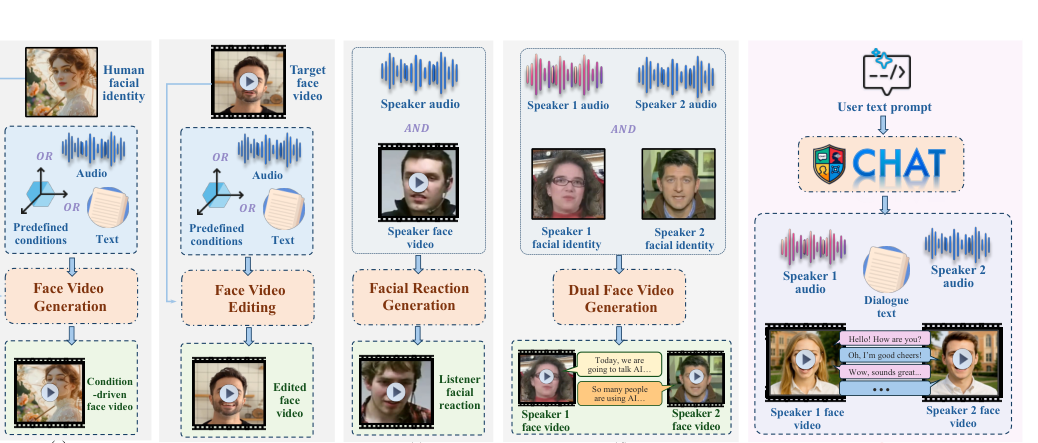 ECCV 2026
ECCV 2026
-
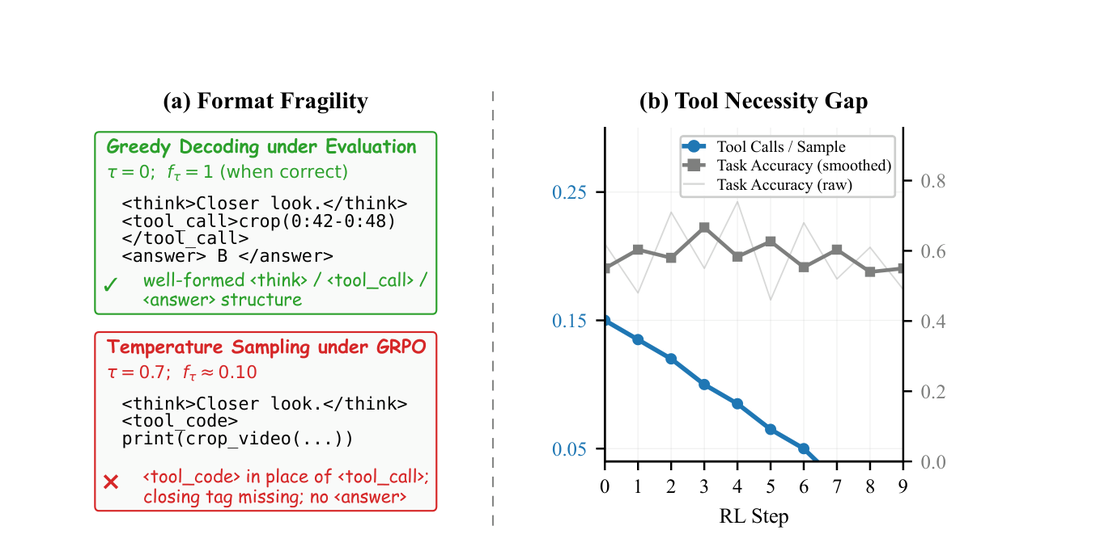 Tech Report
Tech Report
-
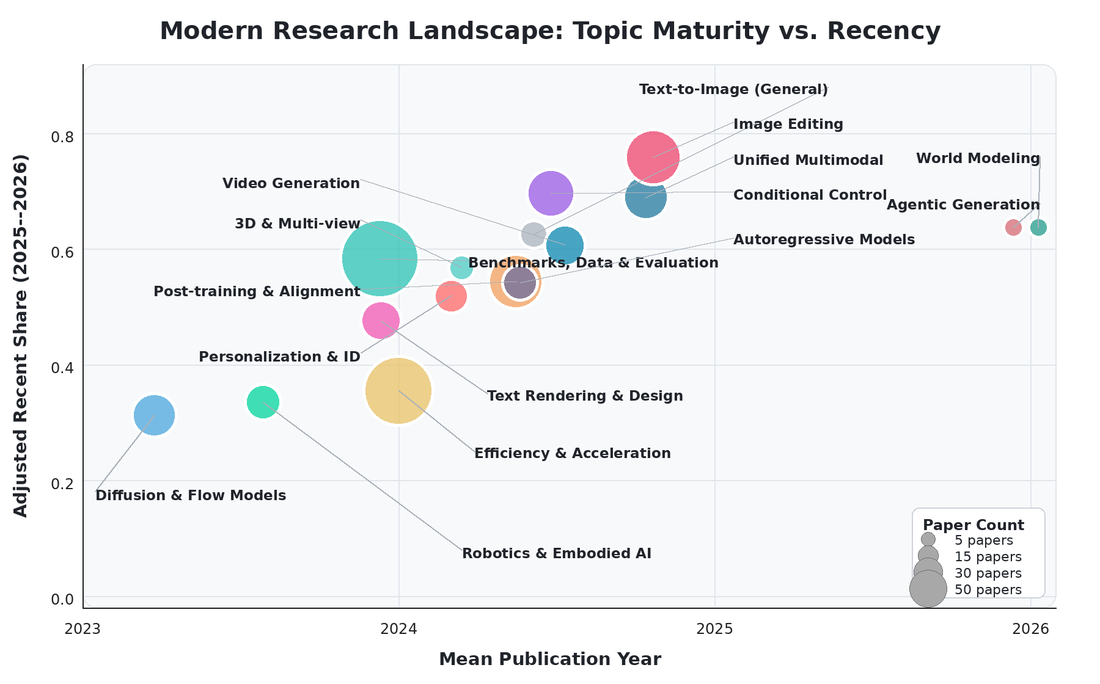 Tech Report
Tech Report
-
 Tech Report
Tech Report
-
 SIGGRAPH Asia 2025
SIGGRAPH Asia 2025
-
 ACL 2026
ACL 2026
-
 CVPR 2026
CVPR 2026
-
 Tech Report
Tech Report
-
 Renewable Energy
Renewable Energy (SCI Q1 TOP, IF = 9.0)
Renewable Energy
Renewable Energy (SCI Q1 TOP, IF = 9.0)
-
 FRL
Finance Research Letters (SSCI Q1 TOP, 1/111, IF = 10.4)
FRL
Finance Research Letters (SSCI Q1 TOP, 1/111, IF = 10.4)
↓ scroll to see more publications
Services
Conference Reviewers
- CVPR, ECCV, ICCV, ICLR, NeurIPS, ICML, ACL, EMNLP, AAAI, SIGGRAPH Asia, WWW, KDD
Journal Reviewers
- IJCV, CVIU, TMM, TIP
Powered by Jekyll and Minimal Light theme.